Of Virtual Machines, Trace Synchronization And NTP
The problematic
When tracing from virtual machines and correlating the data taken on those machines, the issue of timestamps comparison arises. Since the trace events are from different machines who each use a different clock, their timestamps cannot be compared directly as they do not have the same time reference.
A few mechanisms exists:
-
machines can have their time set through NTP, so their timestamps should be close, if in the same timezone. Newer kernels have a module to improve synchronize between kvm host and guests.
-
Trace Compass provides a trace synchronization mechanism using a convex hull algorithm to bring the time reference of other traces to that of a base trace, if the trace contains communication events that can be uniquely matched from one machine to the other.
-
It is also possible to just set a time offset to a trace.
Each of those methods has its pitfalls for virtual environments, which will be discussed below.
Trace Synchronization
But first, why trace synchronization?
If 2 machines do not communicate, then they can be studied independently, there is no need to synchronize them, except approximatively if we want to see together similar events, but in those cases, synchronization has no meaning and we can draw no conclusion regarding the interaction between traces.
But when machines have relations with another, say because they communicate through the network or have shared resources, then their traces are related and should be studied together as one, sharing a common time reference for their events. That requires specific events that can be used to map something happening in one trace (the cause) to something happening in the other trace (the effect). To consider the synchronization as accurate, the cause must always happen before its effect and the latency between them must be as close as possible to the real latency of those events.
To complicate things, clocks in a computer system are not perfectly linear in time and between machines, their speeds can be slightly different and over time, a drift can cause any linear approximation between them to fail.
There’s a few cases of machine communication that requires trace synchronization:
-
Through the network: In those cases, events from each trace are independent, but once in a while, there’s an exchange of information between the machines that triggers events that can be matched between traces (for example, TCP packets generate events that can be uniquely matched). The latency can be in the milliseconds and events happening in between do not have impacts on the other machine.
-
In a virtualized environment: In those cases, traces from multiple machines actually happen on the same physical machine, sharing the same physical resources and requiring actual actions by drivers on the physical machine. Events happening on the guests can have a direct impact on the host. And if we are tracing a virtualized environment, it’s usually to find out what’s happening, where a latency comes from, either from a guest or the host and why, what triggers it. In an ideal world, they would all be using the same clock to exactly match their timestamps, but the world is not ideal, so there’s a need to synchronize them at the sub-microsecond level as much as possible to really be able to analyze potential causality between events.
Trace Compass provides the Event Matching Latency analysis with a few views to allow users to better understand the communication between traces and help them choose the best method for a given use case.

-
The scatter graph shows the latencies in time of message exchanges, with a different color for each pair of source/destination.
-
The event match latencies table contains all the latencies and can be sorted by different values
-
The event match latency statistics show the latency statistics (minimum, maximum, average, standard deviation and count) for every pair of source/destination.
The scatter graph and statistics are the most useful data and some screenshots will be shown below.
NTP
The Network Time Protocol is a network protocol designed to query time servers to synchronize computers as close as possible to the Coordinated Universal Time (UTC) while mitigating network latencies. When time servers are on the internet, NTP can maintain time to within tens of milliseconds, while on a LAN, it can achieve better than one millisecond. (Information taken from wikipedia).
The following image shows the evolution of the network latency between a virtual machine and its host synchronized with NTP on a local network. The latency is the difference between the timestamp of the reception event and the timestamp of the host event. Each colored serie represents the exchange of TCP packets sent by one machine and received by another.
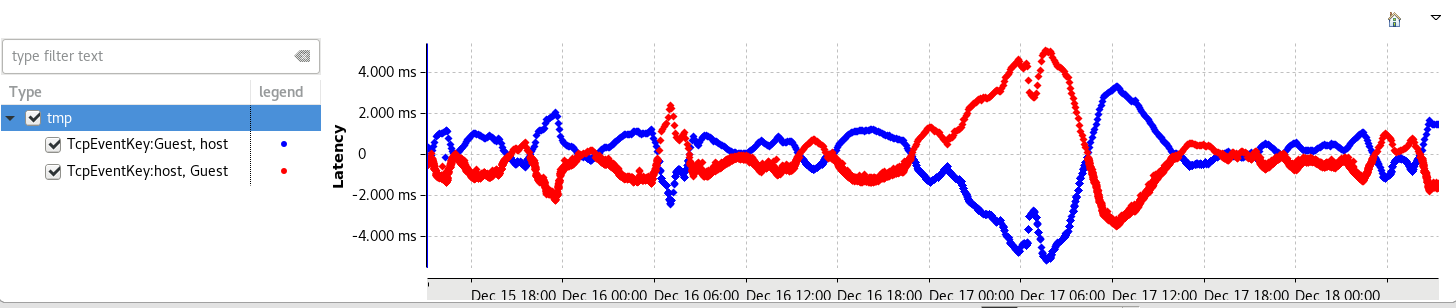
The series are symmetrical as expected as TCP is symmetrical in both directions. But some latencies are negative, which means that if we use those timestamps to analyse the traces, in one direction, the packet would be received before it is sent! We note that NTP tends to always slowly bring the latency back to an average of ~500 us, but with an important standard deviation of 1.5ms.
In a virtual machine environments though, this latency is unacceptable. Interactions between host and guest happen at the micro-second level and this can make a difference when trying to find out which thread on the guest caused a series of kvm exit/entry on the host. If it’s a problem we’re trying to solve, having the wrong guilty thread can make a dramatic difference. Thankfully, a solution exists to improve the synchronization betwen hosts and guest since linux 4.11: PTP devices for KVM and Hyper-V. It uses a driver that returns the host’s realtime clock so that guests’ NTP synchronize with high precision. For more information, this article explains some notions of timekeeping with linux VMs.
In the guest, one needs to load the ptp_kvm kernel module
$ echo ptp_kvm > /etc/modules-load.d/ptp_kvm.conf
And then add this ptp device to the NTP configuration
$ echo "refclock PHC /dev/ptp0 poll 3 dpoll -2 offset 0" >> /etc/chrony.conf
We traced many days of TCP packet exchanges between VMs and host to test the latency and consistency of this NTP method. VMs and host are up to date archlinux (as of December 20, 2017). VMs are running on qemu 2.11, with kvm enabled.
With VMs pretty much idle except for a ping between host and guests, we have the following results in a 4 days period:
| TCP packet exchange | Average | Min | Max |
|---|---|---|---|
| Host -> Guest1 | 165µs | 10.686µs | 3.427ms |
| Guest1 -> Host | 28µs | 5.603µs | 209.570µs |
| Host -> Guest2 | 164µs | 10.155µs | 916.349µs |
| Guest2 -> Host | 27µs | 5.762µs | 586.708µs |

For comparison, the average latency of network packets sent to themselves by host and VMs is 4µs.
But if we have the virtual machine execute some workload (using the stress program, stressing CPU, memory, hdd, etc) during the traced time, we see totally different results.
| TCP packet exchange | Average | Min | Max |
|---|---|---|---|
| Host -> Guest1 | 412µs | -23.818ms | 22.223ms |
| Guest1 -> Host | -246µs | -21.940ms | 23.899ms |
| Host -> Guest2 | 140.255µs | 6.486µs | 1.429ms |
| Guest2 -> Host | 24µs | -5.168µs | 783.799µs |
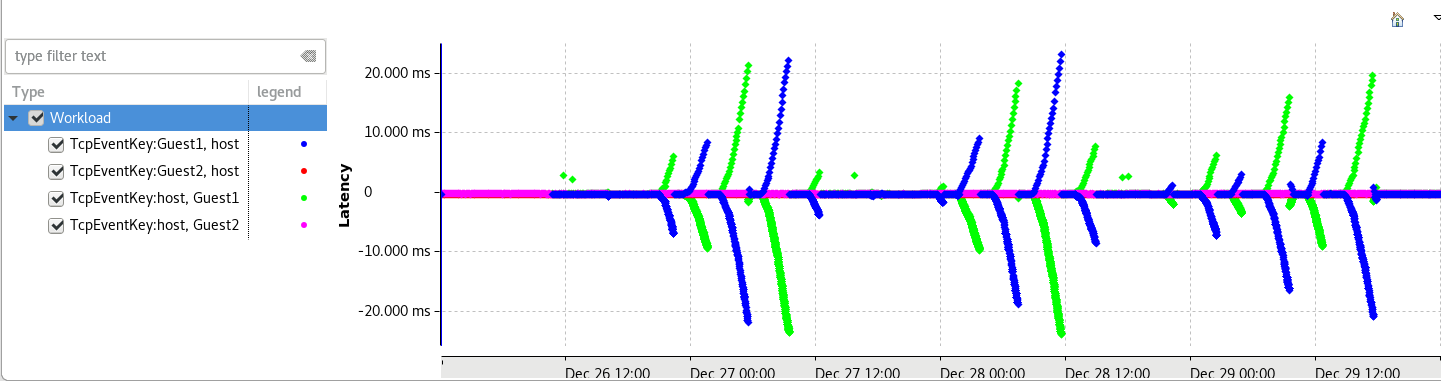
Both guests were executing the same workload, but we observe that Guest1’s clock periodically drifts away from the host’s. And unlike the slow adjustment of a normal NTP protocol, it is rapidly brought back to reason at some point and then starts drifting the opposite way! Both machines are configured similarly to the best of our knowledge, but obviously there’s a difference somewhere.
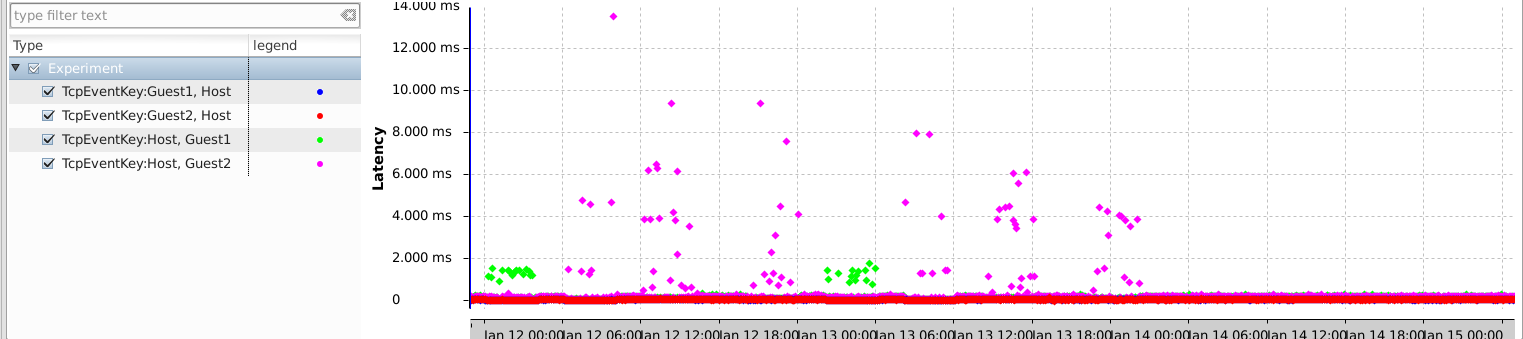
Edit: Actually, our chrony.conf file on Guest1 contained the ptp device for the refclock but also an ntp server was configured. It didn’t seem to like it as there was quite a few “Can’t synchronise: no majority” messages in the logs and it failed to correctly synchronize for some time. Removing the ntp server from the configuration fixed the problem, as the next figure shows. Some messages have a higher latency but it is positive and goes only one way, so it is simply a higher latency message, no sign of bad synchronization.
Convex Hull Synchronization Algorithm
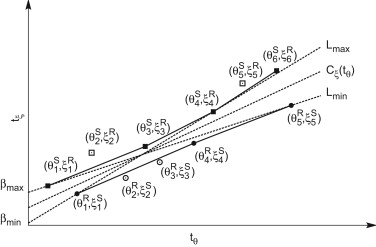
The convex hull synchronization algorithm aims to find a linear formula correlating the clocks from 2 traces by taking only the more meaningful packets (ie those with lower latency) in both directions. This gives 2 convex hulls from which we draw the lines with least and most slope and find the bissect between those lines. The following image taken from Masoume Jabbarifar’s article summarizes the principle.
To be able to use this algorithm, the traces must exchange messages such that one event from a machine can be uniquely matched with one event from the other machine. TCP packets is an example of events that have these characteristics (the seq, ack_seq, and flags fields are unique between sender and receiving, even across internet).
This algorithm guarantees that a packet is always sent before it is received and accounts for the latency between the events. It also assumes that the clocks can be correlated with a linear formula, ie that each clock is constant in time, which tends to be false, as the trace gets longer. Also, the larger the natural latency of the message exchange, the longer it will take before the linear assumption fails.
With NTP server on the local network and a small load, the convex hull algorithm is good for 15 minutes. With the PTP_kvm module, then the algorithm is valid for more than 12 hours.
But our traces are longer than that: the algorithm fails and the times diverge even more than simple network NTP! With the VMs idle:
| TCP packet exchange | Average | Min | Max |
|---|---|---|---|
| Host -> Guest1 | 197µs | -1.835µs | 3.503ms |
| Guest1 -> Host | -3.504µs | -74.750µs | 214.011µs |
| Host -> Guest2 | 3.211ms | -382.627µs | 7.114ms |
| Guest2 -> Host | -3.028ms | -6.507ms | 516.893µs |

Time offsetting
This synchronization technique consists in manually giving a time offset to one of the traces, ie a value that will be added to every timestamp of one trace.
We observed in a the idle guests case that the latencies is constant over time, but not symmetrical, as if there was an offset in some of the traces. We can try to offset the guests in such a way that the average latencies in both direction are closer together, while still keeping a minimal latency between the machines.
Given the minimal latencies is 10µs for reception and 5µs for sending, there is not that much margin to offset. The small asymmetry may actually be normal in VMs as there is possibly some hypervisor operation to do upon receiving a packet which is not required when sending?
We’ll still try to add an offset of -5µs to Guest1 and Guest2. The following table and image show the results. For what it’s worth, it reduces the latency between machines by 10µs…
| TCP packet exchange | Average (without offset) | Average (with offset) | Min |
|---|---|---|---|
| host -> Guest1 | 165µs | 160µs | 5.686µs |
| Guest1 -> host | 28µs | 33µs | 10.603µs |
| host -> Guest2 | 164µs | 159µs | 5.155µs |
| Guest2 -> host | 27µs | 32µs | 10.762µs |
Use case
So, the preceding traces allowed us to better understand our virtual environment. From now on, we can assume that using the ptp_kvm module for clock synchronization between guests and host should be enough to give a good time synchronization between machines, without additional mechanisms. Let’s now try more complete traces on this environment.
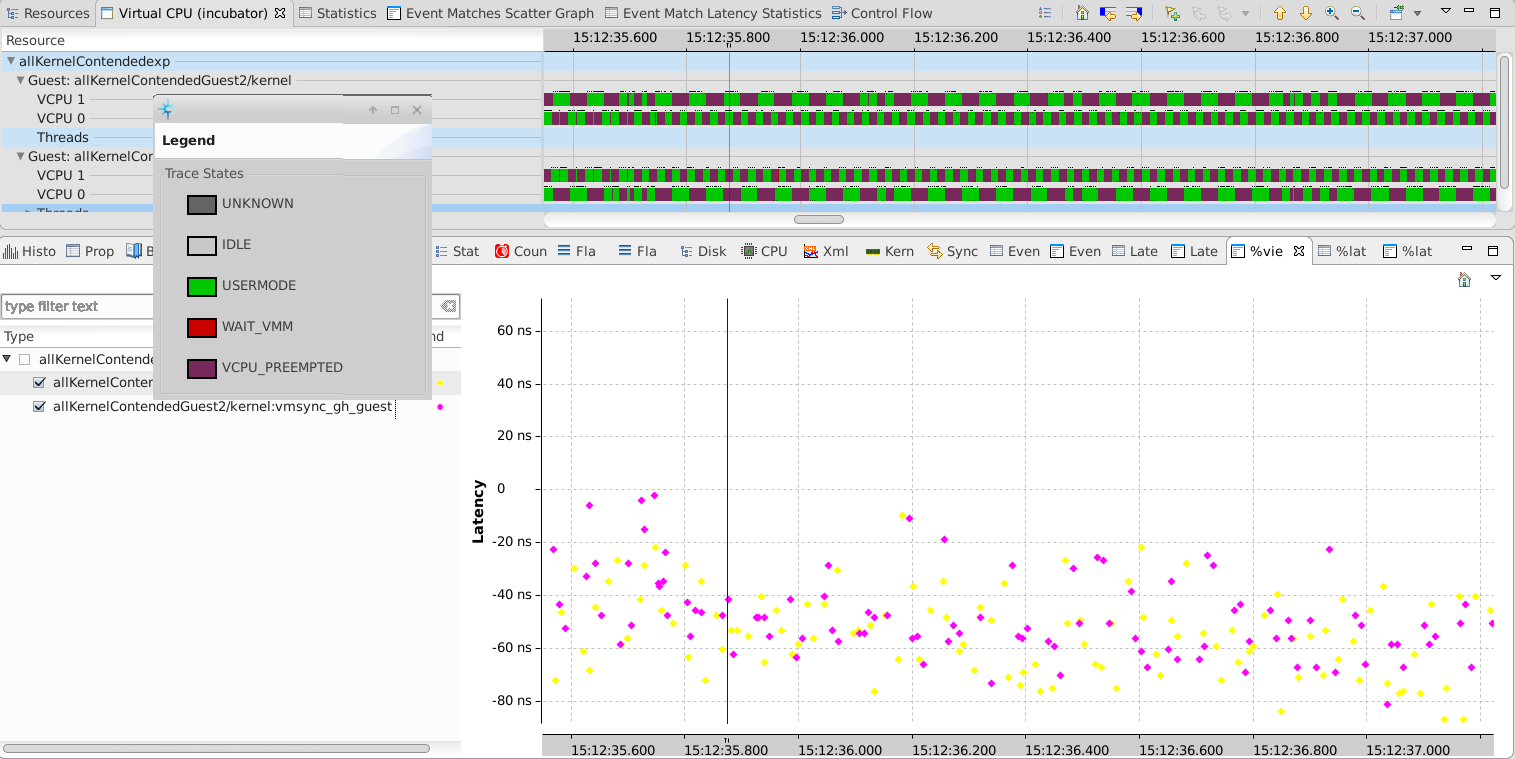
We need to make sure that no event from the guest happens while the Virtual CPU (VCPU) is scheduled out or in hypervisor mode. The Virtual Machine Analysis has been enhanced to mark all events in guest that happen when they shouldn’t (ie the host thread corresponding to the vcpu is scheduled out, or the thread is in hypervisor mode) and show the time difference with the closest VCPU running state.
We ran a ~5 minutes trace, enabling the events required to analyze the system (see the To reproduce section for more details). During that time, we ran a few stress commands (1 minute CPU, 30 seconds IO, 1 minute memory).
In the first scenario, there was no contention on the virtual machines, they could use as much host CPU as they needed, so the number of virtual CPU preemption was low, but there were periods in hypervisor mode. The following chart shows that there are a 220K events happening where no events are expected (out of 15M total events in guests, so about 1.5%), but they have an average latency of 98ns, and they are all, except a handful, within 400 ns.
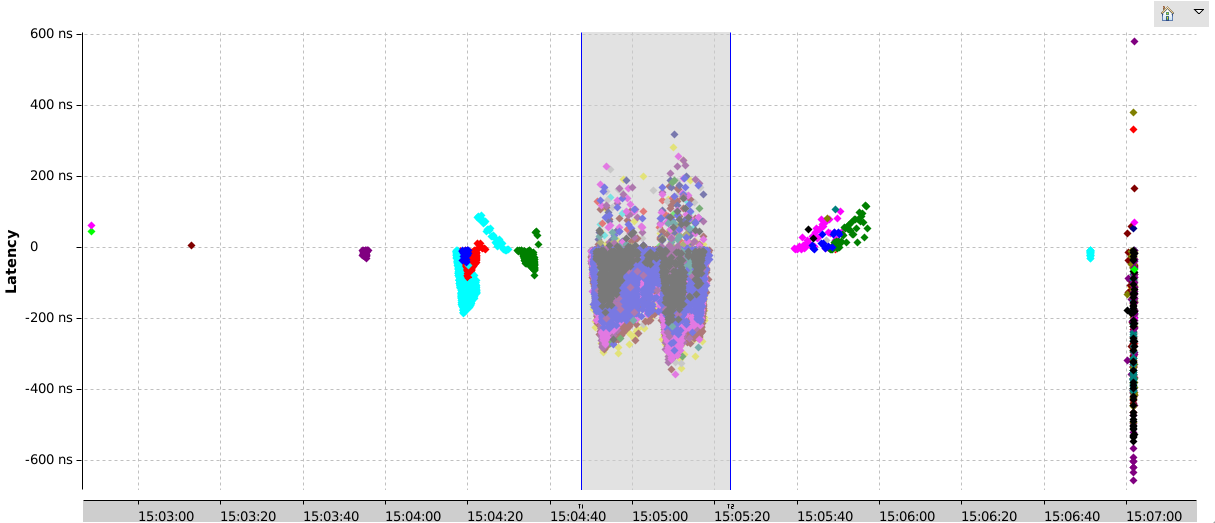
The biggest concentration of such events happened during the stress for IO test. That would be expected as it causes of lot of short exits to hypervisor mode, as shown in the figure below. Knowing that perfect synchronization is not possible, this latency is perfectly acceptable.

Would we get better results by synchronizing with the convex hull algorithm? The synchronization fails for one of the machine. The latency is so low that even in 5 minutes of traces, the drift is important enough so that no linear approximation can be made. In this case, there are 22K bad events with an average latency of 78ns, so yes, we do have better results, though with latency below 100ns, it is debatable whether it is worth the extra tracing and analysis efforts.
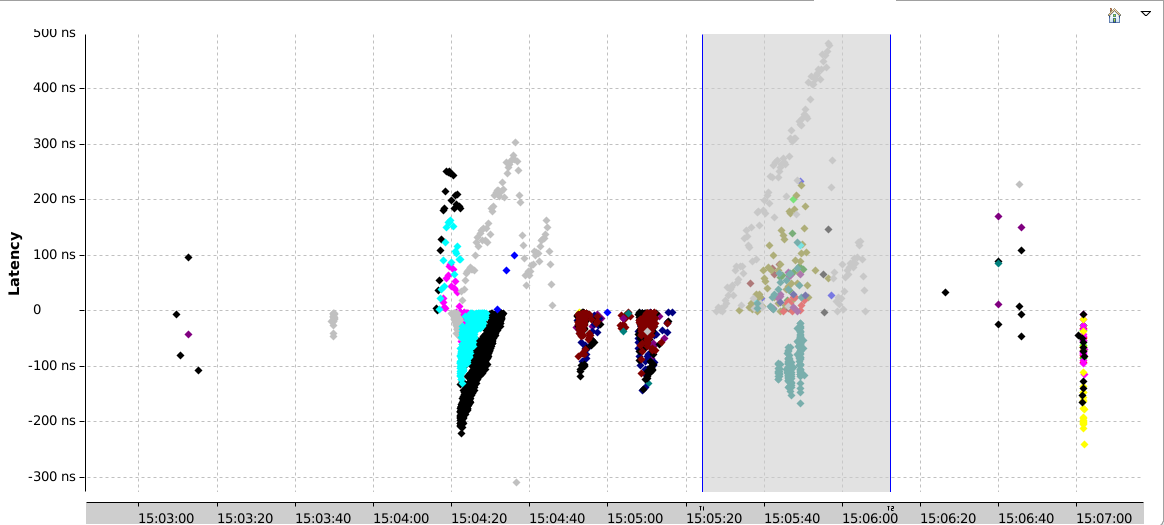
For a second scenario, we forced contention of the VM processes by setting each qemu process the same CPU affinity with the same 2 CPUs, so we have 4 virtual CPUs running on 2 physical ones. In this case, the virtual CPUs are expected to be preempted a lot. From the results, we see that something happened towards the beginning of trace, as is confirmed by the event matching view. With so much latency, the tracing data between machines cannot be considred accurate in that range. Luckily, this is not our region of interest. If it were, we could not conclude anything and should trace again. If we eliminate the start of the trace, as in the second picture below, and consider only the events after, there are 2900 bad events (out of 7M guest events, about 0.04%!), which is unexpectedly good considering the number of preemptions.

The bulk of those events happen during the CPU stress test, where the virtual CPUs get preempted quite often, unlike the not contended experiment where they were running most of the time. With VCPUs preempted half the time, chances of guest events happening in those periods is more likely. But the latencies remain very low, lower than 250ns, similar to the not contended scenario. In that region, the running times of the virtual CPUs varies from around 3 to 30 milliseconds before being preempted, so latencies in the nanoseconds are accurate.
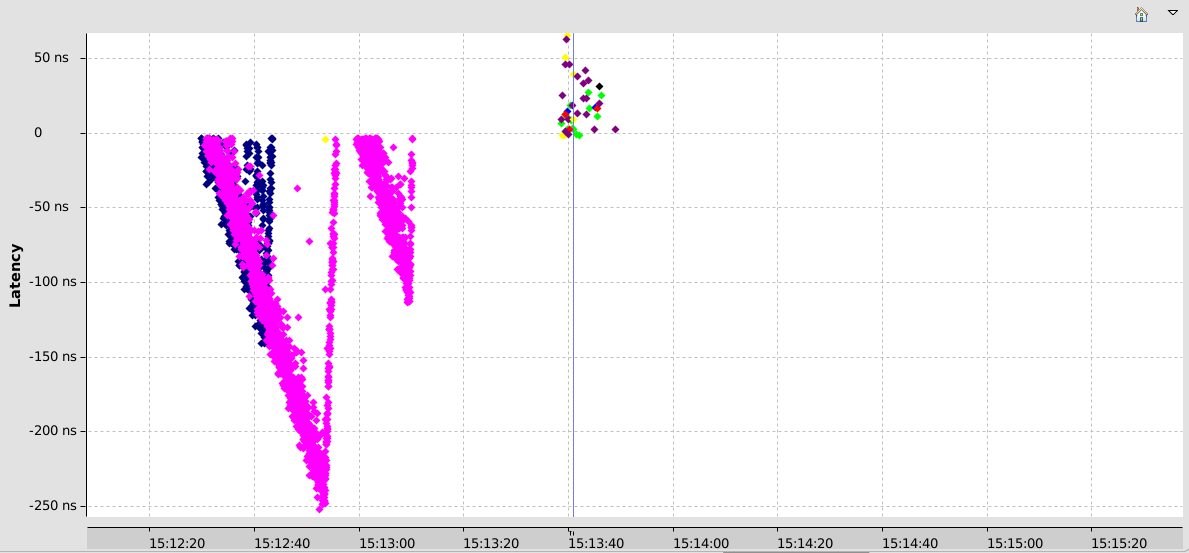
As for synchronizing with the convex hull analysis, because of the timing glitch at the beginning of the trace, the synchronization fails and results are totally wrong. The best would be to run the trace again and hope time keeping will be better.
That’s what we did and this time, we had 1600 bad events (out of 8M guest events), with an average latency of 63ns. That very good! With the convex hull synchronization algorithm, the synchronization fails, with 250K bad events, but with a 52ns latency. Again, it may not be worth the additional effort to synchronize traces this way.
Conclusion
Know your machine’s timekeeping!! Tracing is not something people do for fun, there usually is performance issues, bugs to investigate, problems to solve. When planning on tracing virtual machine, one must understand the necessity of a good time synchronization. The actual investigation can be preceded by a few long traces with only the matchable events. The traces taken this way shouldn’t be too large and the TraceCompass’s Event Matching Latency Analysis can show the behavior of the clocks over time. This can help decide how to synchronize the traces of the investigation.
Ideally, if the NTP synchronization with ptp_kvm is available and stable enough between the machines, then no additional event/synchronization is necessary with the traces. But if not… then the appropriate events need to be enabled, steps may be necessary to make sure those events are generated during tracing time and the appropriate synchronization technique needs to be applied on the traces before any other actual analysis.
To reproduce
For these experiments, I traced using latest lttng-tools and lttng-modules. To analyze the traces, I used Trace Compass from source code.
For the long duration network communication traces, I used the following commands for tracing in guests and host, enabling only events for network packets:
lttng create
lttng enable-channel --kernel --num-subbuf 16 --subbuf-size 1024K more-subbuf
lttng enable-event -k --channel more-subbuf net_dev_queue,netif_receive_skb,net_if_receive_skb
lttng start
I used this script on the host to ensure a frequent, but not too verbose communication between machines:
#!/bin/bash
while true; do
ssh virtual@machine1 ls
ssh virtual@machine2 ls
sleep 200
done
For the long traces, a special version of lttng-modules for qemu/kvm analyses needs to be compiled, with the kernel sources for the kvm events. Refer to the Trace Compass Incubator’s Virtual Machine feature documentation for more information on compiling the tracer. The following commands lines were used to create the tracing session:
sudo modprobe lttng_probe_addons
# Enable one of the following line for tracing on host or guest respectively
sudo modprobe lttng_vmsync_host
sudo modprobe lttng_vmsync_guest
lttng create
lttng enable-channel --kernel --num-subbuf 16 --subbuf-size 1024K more-subbuf
# scheduling
lttng enable-event -k --channel more-subbuf sched_switch,sched_waking,sched_pi_setprio,sched_process_fork,sched_process_exit,sched_process_free,sched_wakeup
lttng enable-event -k --channel more-subbuf irq_softirq_entry,irq_softirq_raise,irq_softirq_exit
lttng enable-event -k --channel more-subbuf irq_handler_entry,irq_handler_exit
lttng enable-event -k --channel more-subbuf --syscall --all
lttng enable-event -k --channel more-subbuf lttng_statedump_process_state,lttng_statedump_start,lttng_statedump_end,lttng_statedump_network_interface,lttng_statedump_block_device
# Block I/O
lttng enable-event -k --channel more-subbuf block_rq_complete,block_rq_insert,block_rq_issue
lttng enable-event -k --channel more-subbuf block_bio_frontmerge,sched_migrate,sched_migrate_task
# cpu related
lttng enable-event -k --channel more-subbuf power_cpu_frequency
# network events
lttng enable-event -k --channel more-subbuf net_dev_queue,netif_receive_skb,net_if_receive_skb
# timer events
lttng enable-event -k --channel more-subbuf timer_hrtimer_start,timer_hrtimer_cancel,timer_hrtimer_expire_entry,timer_hrtimer_expire_exit
# vm EVENTS
lttng enable-event -k --channel more-subbuf vmsync_hg_guest,vmsync_hg_host,vmsync_gh_guest,vmsync_gh_host
# kvm events, comment this line on guests
lttng enable-event -k --channel more-subbuf kvm_x86_entry,kvm_x86_exit,kvm_x86_hypercall,kvm_x86_hv_hypercall
lttng start
As for the analyses used in Trace Compass to display event matching latencies and virtual machines’ bad events, the former is still under review and can be obtained by checking out this patch (it should be integrated in Trace Compass soon). The latter will soon be included in the Virtual Machine And Container Analysis incubator feature.