Trace Compass Scripting Engines Benchmarks
Trace Compass Scripting
Scripting support has recently been introduced in Trace Compass through an incubator feature. This feature uses the Eclipse EASE Framework for the various scripting engines and integration with the application.
It gives users the flexibility to do their own analyses / views from the traces data. Or to run scripted workflows when opening traces so interesting areas of the trace are automatically highlighted. This github repo contains a few example and utility scripts that can be run with Trace Compass.
One question the users asked is which engine to use? What’s the performance impact of each. Our first answer was that of course there would be a performance hit by running a script, but it should not be that high and engines should be quite similar to the language they provide. But experimental results have shown quite differently. So we have run a set of benchmarks for the various scripting engines. They are summarized here.
TLDR: For javascript, performances are similar for all engines, though rhino does not work for all scripts as it does not support very well calling java methods with multiple signature. For python, use jython if you make a lot of calls to java and don’t need external python libraries, py4j has a heavy performance cost when calling java methods or using java objects.
Scripting engines
The main scripting languages used by Trace Compass users are javascript and python. For each of those, EASE provides 2 engines: nashorn and rhino for javascript and jython and py4j for python.
Both javascript engines run the javascript code on the Java Virtual Machine. nashorn (rhino in german) is a new implementation of the aging and under-performant rhino engine. Both should run any javascript code, though nashorn better supports the latest features.
For python though, both engines are very different:
jython is a Java implementation of the python language. A script written in python and run in jython will thus be run in Java. A jython script can import any java class or package like it would a python library. For instance, one could just add an import statement from org.eclipse.tracecompass.tmf.core.trace import TraceManager and then call any method of TraceManager directly in the code. On the flip side, it cannot import any external python library.
py4j runs the script in a python interpreter and uses a gateway to communicate with a Java Virtual Machine, through a network socket. The script thus has access to all the python libraries available to the interpreter, as well as to the Java classes and objects. But the socket communication between java and python brings an additional overhead that we will measure with the benchmarks.
Additionally, because of the differences between jython and py4j, scripts may need to be written differently for both engines, like the callbacks from java to script for example, as we will highlight in the benchmark scripts descriptions. Also py4j needs to explicitly detach java objects from the script engine to avoid filling the memory.
Benchmarks
We have run a few benchmarks for the different script engine with EASE in Trace Compass
-
Empty Script: We ran a simple one-liner script that assigns an integer to a variable. This benchmarks serves to show the time it takes EASE to bootstrap a script with the given engine.
-
Native Computation: This benchmark runs a computation on numbers in each of the script languages. It does not interact with the java application. This will compare the scripting language performances for the engine itself.
-
Computation: script calls Java: In this benchmark, each script calls a java method once and the computation is entirely done in Java.
-
Computation: script callback for each value: For this case, the script calls a Java method that will do the computation loop, but it provides a callback function that the java method calls to obtain the next value. Note that this benchmark was taking so much time that the number of computations was decreased by 2 orders of magnitude compared to the other computation benchmarks.
I’ll take the opportunity here to show how to implement callback methods for the various script engines. The signature of the Java method receiving the callback is as follows:
@WrapToScript
public void doLoopWithCallback(Function<Long, Number> function) {
[...]
long number = 3;
long value = function.apply(number).longValue();
}
The return value of the function is a Number instead of a specific type as some scripting languages may have values of type double or float or long. The Number reduce the hassle on the callback.
In javascript, callbacks are possible with the nashorn engine, it is not possible with rhino(at least I haven’t found a way)
function compute(value) {
if (value % 2 == 0) {
return value / 2;
}
return 3 * value + 1;
}
doLoopWithCallback(compute)
For python, jython and py4j have different implementations for the callback. jython has direct access to the classes so can easily extend the Function class
# Jython
from java.util.function import Function
class CallbackFunction(Function):
def apply(self, value):
if value % 2 == 0:
return value / 2
return 3 * value + 1
callbackFunction = CallbackFunction()
doLoopWithCallback(callbackFunction)
py4j, on the other hand, must do it differently. This approach will unfortunately not work with jython.
# Py4j
class CallbackFunction(object):
def apply(self, value):
if value % 2 == 0:
return value / 2
return 3 * value + 1
class Java:
implements = ['java.util.function.Function']
callbackFunction = CallbackFunction()
doLoopWithCallback(callbackFunction)
-
Computation: script calls java for each value: This case is the opposite of the previous. The computation loop is in the script, but the script calls a java method to obtain the next value.
-
Read trace: This benchmarks reading a trace, a typical use case for Trace Compass users. It does not do anything with the events at this point. This benchmark is run with a small (85k events) and large (5M events) kernel traces.
-
TID analysis: In this benchmark, the trace is read and values are stored to a state system, another typical case in Trace Compass. This script is the equivalent of the
TID analysisfor kernel traces, so we can compare with the execution of the analysis in Java, but also in XML. The benchmark is run with the same kernel traces as previously.
The results are shown in the graph below, notice the logarithmic scale.
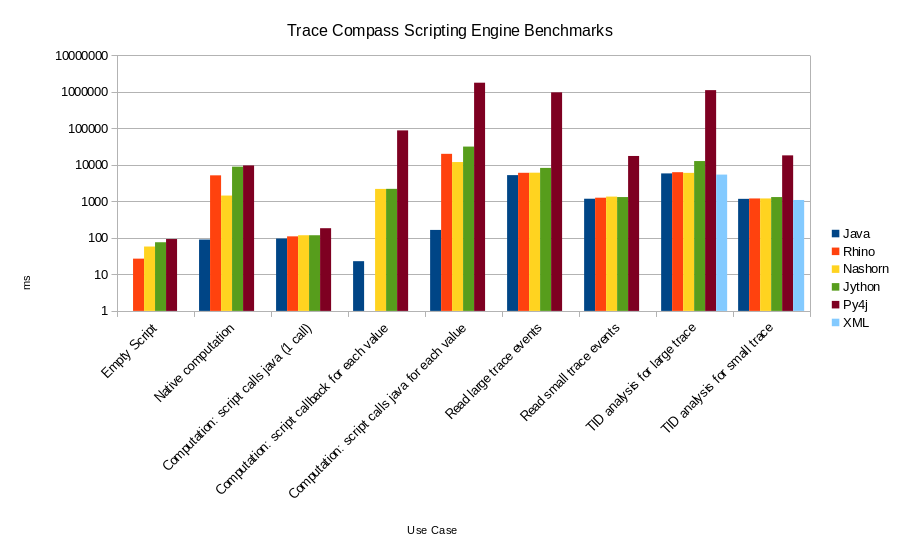
For Trace Compass users, the important take-away is that except for py4j, scripting engines have similar performances and the overhead compared with pure java for similar workload is negligible.
Mitigate the py4j performance hit
From the Scripting API
py4j is a special case though: its communication mechanism with Java has such a high overhead that its usage is prohibitive for everything but small traces. But py4j’s main advantage is the possibility to leverage all the external python libraries available. A use case of our users is to do machine learning with trace data and there exists a lot of python libraries out there to do so. So how could we take advantage of that without having to wait forever?
One way to do so is, knowing the cost of passing Java objects to/from script, to reduce the number of passages at the source. The API should allow to minimize the object passing. For instance, when reading a large kernel trace, not all events are required to run our analysis. If we can reduce the number of events passed between the script and the Java code, then the performances should be improved.
In our benchmarks running the TID analysis, the only event we are interested in is the sched_switch, so we add this event to the event iterator before starting to iterate and only those events will be returned.
loadModule("/TraceCompass/Trace")
var trace = openMinimalTrace("Tracing", argv[0])
eventIterator = getEventIterator(trace);
eventIterator.addEvent("sched_switch")
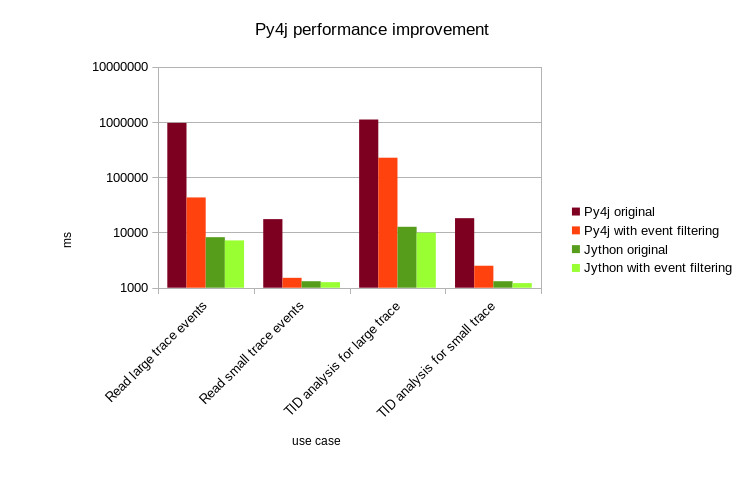
The following chart shows the performance improvement with this approach. Even though performance is improved by an order of magnitude, it is still far off the jython performances without event filtering.
Mix engines
Another approach would be to mix python scripting engines when external libraries are requested. Those libraries’ API often requires a specific data structure to run on, so a jython script can prepare this data structure using the trace data and then call a py4j script to act upon this data. For this, EASE’s Scripting module can be handy, with its fork method and using shared objects to pass data to the other script
The following script is a python script that can be run with the jython engine that prepares a dictionary object and passes it as a json string to another python script run with py4j. It then forks a new script execution with the py4j engine and waits for the result.
#jython script
loadModule("/System/Resources")
loadModule("/System/Scripting")
import json
# Prepare a dictionary object to be passed to the other script
dictionary = {}
for x in range(100000):
dictionary[str(x)] = x
# Call the other script
filePath = "workspace://myProject/callee.py"
file = getFile(filePath);
if file is None:
print("Callee script not found: " + filePath)
exit()
myStr = json.dumps(dictionary)
setSharedObject("myStr", myStr)
# Run the script with the name of the variable as parameter and wait for the result
result = fork(file, "myStr", "org.eclipse.ease.lang.python.py4j.engine")
result.waitForResult()
# Should print 'some return string'
print(result)
The following py4j script receives the name of a shared object in argument and gets the corresponding string, loads it as a dictionary, does something with it and returns.
#py4j script
loadModule("/System/Scripting")
import json
# Get the json string as a shared object and load as dictionary
obj = getSharedObject(argv[0])
dictionary = json.loads(obj)
sum = 0
for x in dictionary:
sum += dictionary[x]
print("sum " + str(sum))
exit("some return string")
Note that the dictionary object was dumped as a json string before passing it as a shared object. If it was passed directly, Java would have converted it to a java HashMap and getting each element would require calls to java, which is what we want to avoid here.
How to change the scripting engine?
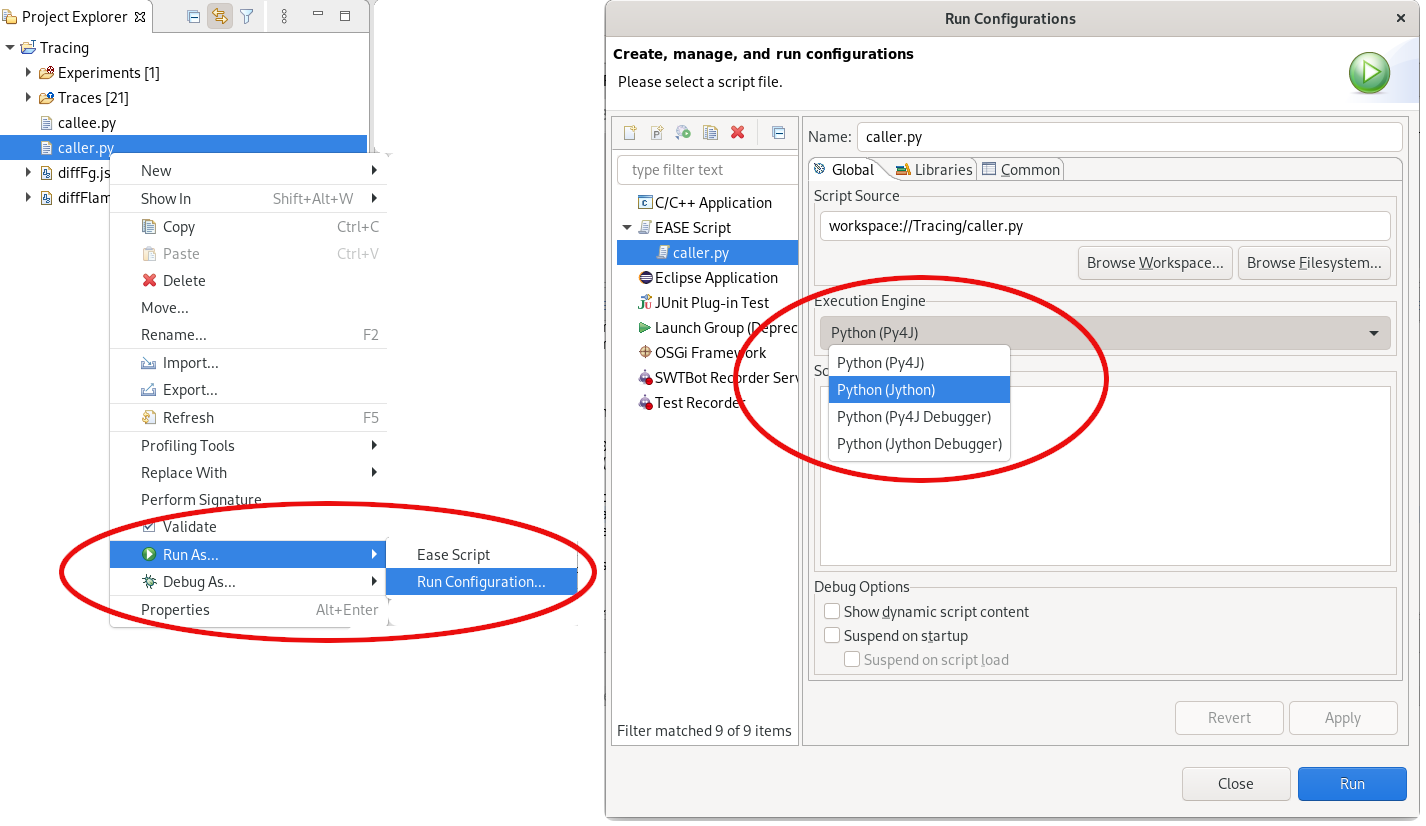
We’ve been discussing how different python engines behave differently. But how do we change the engine running the script? The following screenshot shows how to do so:
-
Right-click on the script and selection
Run As...->Run Configuration... -
In the dialog that opens, select the right configuration (the one for the file to run), then select the engine from the
Execution Enginedrop box. -
Press
ApplyorRun
References
The benchmarks executed in this script are now, or will shortly be, part of the Trace Compass code base, in the org.eclipse.tracecompass.incubator.scripting.ui.tests plugin, in the perf directory. The scripts themselves are in the scripts/perf directory of the plugin.
See also this git repo for example scripts and links to all available documentation.